.jpg)




前言: 在 Oracle EBS 的运维生涯中,处理千万级的数据表已是挑战。但当一张核心接口表的数据量突破 1.6 亿 大关时,常规的 DML 操作将彻底失效。本文将复盘一个因配置疏忽导致亿级数据灾难,并最终通过并行技术(Parallel)安全化解的真实案例。
1. 灾难现场:被遗忘的“蓄水池”
由于系统的 Planning Manager(计划管理器)自上线以来从未启用,导致 MRP 模块的冲销接口表 MRP_RELIEF_INTERFACE 变成了一个只进不出的“蓄水池”。
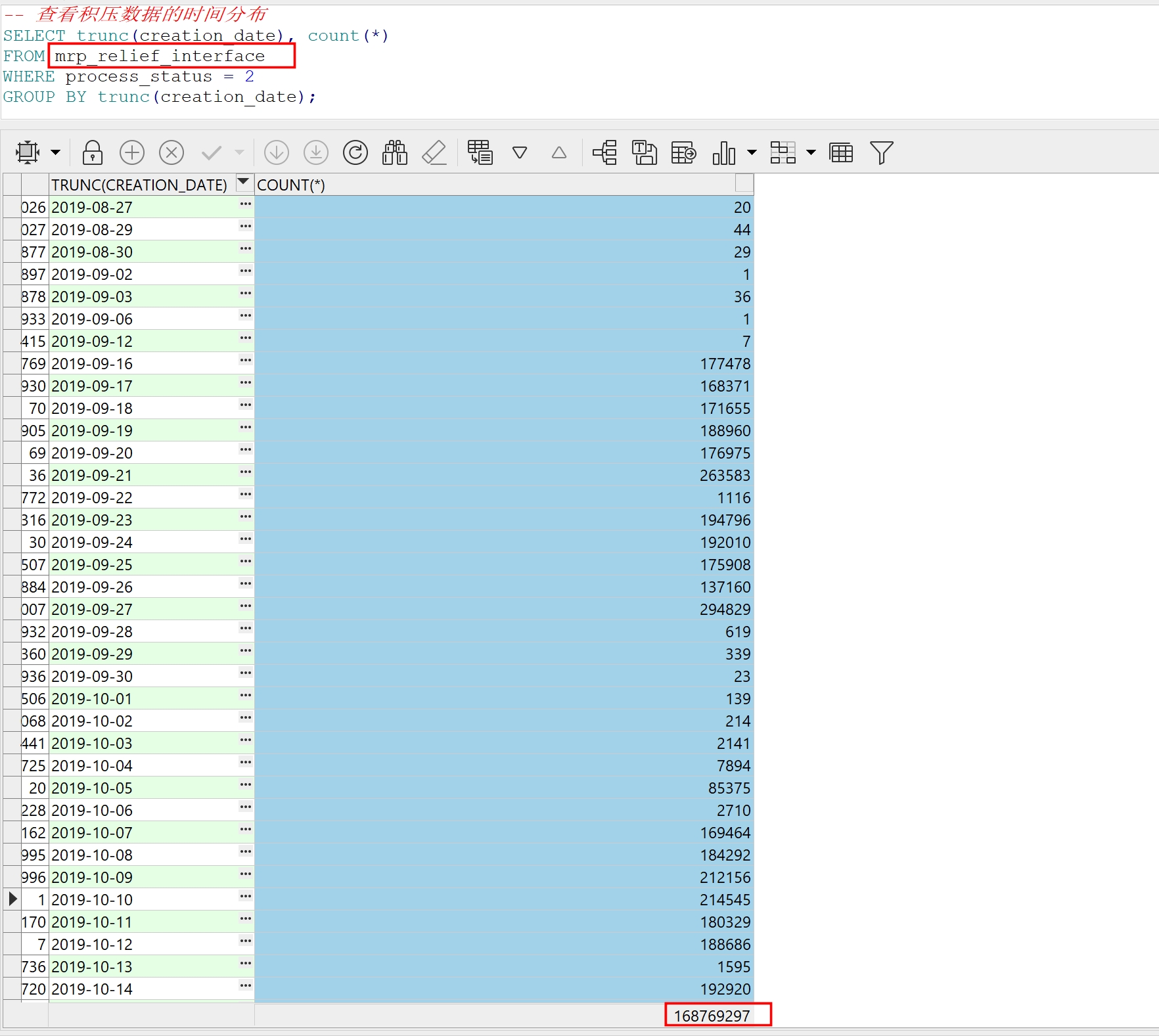
当系统运行缓慢、计划任务陷入瘫痪时,通过底层 SQL 诊断发现,积压量已达 168,769,297 条。
利用 creation_date 分组查看,可以看到数据积压呈现明显的长期爆发态势:
SQL
-- 诊断 SQL:查看待处理数据的时间分布
SELECT trunc(creation_date), count(*)
FROM mrp_relief_interface
WHERE process_status = 2
GROUP BY trunc(creation_date)
ORDER BY trunc(creation_date) ASC;
现场截图:
从 2019 年起,日增量峰值经常突破 20 万条,积压至今已成天文数字。
2. 优化方案:为什么不能直接 DELETE?
面对 1.6 亿数据,传统的 DELETE 语句会导致 Undo 表空间溢出 且严重拖慢系统 I/O。资深顾问的策略是:备份关键存量 -> TRUNCATE 释放高水位线 -> 并行回写 -> 环境重构。
🛠️ 核心实战脚本
本方案利用了 Oracle 的 并行处理(Parallel)、最小化日志(NOLOGGING) 与 直接路径插入(APPEND) 提示。
SQL
/* EBS 运维实战:mrp_relief_interface 1.6 亿数据清理
注意:操作前必须停止 Planning Manager 并确保无相关请求运行
*/
-- 1. 全量备份数据 (8 线程并行 + 最小化日志)
CREATE TABLE CUX_MRP_RELIEF_INTERFACE_BKP
NOLOGGING PARALLEL 8 AS
SELECT /*+ PARALLEL(8) */ * FROM MRP.MRP_RELIEF_INTERFACE;
-- 2. 备份 2025 年及以后的有效业务数据 (作为回写火种)
CREATE TABLE cux_mrp_relief_interface_new
NOLOGGING PARALLEL 8 AS
SELECT /*+ PARALLEL(8) */ * FROM mrp.mrp_relief_interface
WHERE creation_date >= TO_DATE('2025-01-01', 'YYYY-MM-DD');
-- 3. 截断原表 (瞬间释放 1.6 亿数据占用的 HWM)
TRUNCATE TABLE mrp.mrp_relief_interface;
-- 4. 并行直接路径回写
INSERT /*+ APPEND PARALLEL(8) */ INTO mrp.mrp_relief_interface
SELECT /*+ PARALLEL(8) */ * FROM cux_mrp_relief_interface_new;
COMMIT;
-- 5. 重建索引 (使用 ONLINE 关键字减少锁表)
ALTER INDEX MRP.MRP_RELIEF_INTERFACE_N1 REBUILD ONLINE NOLOGGING PARALLEL 8;
ALTER INDEX MRP.MRP_RELIEF_INTERFACE_N2 REBUILD ONLINE NOLOGGING PARALLEL 8;
ALTER INDEX MRP.MRP_RELIEF_INTERFACE_U1 REBUILD ONLINE NOLOGGING PARALLEL 8;
-- 6. 还原索引为单线程模式 (防止后续业务产生不必要的并行计划)
ALTER INDEX MRP.MRP_RELIEF_INTERFACE_N1 NOPARALLEL;
ALTER INDEX MRP.MRP_RELIEF_INTERFACE_N2 NOPARALLEL;
ALTER INDEX MRP.MRP_RELIEF_INTERFACE_U1 NOPARALLEL;
-- 7. 收集统计信息 (必做,否则 CBO 优化器将维持错误的执行计划)
EXEC FND_STATS.GATHER_TABLE_STATS('MRP', 'MRP_RELIEF_INTERFACE');
3. 进阶笔记:资深顾问的细节把控
在处理亿级数据时,以下三个细节决定了操作的专业高度:
索引状态恢复:重建时使用
PARALLEL 8是为了提速,但完成后必须NOPARALLEL,否则日常单条 DML 可能引发资源争用。安全闭环:由于使用了
NOLOGGING,操作后应立即发起一次数据库增量/全量备份,确保存量数据在介质损坏时可恢复。架构预防:若业务量持续巨大,建议将此类接口表改造为分区表,未来清理历史数据只需
DROP PARTITION,实现秒级物理剥离。
4. 总结
面对 1.6 亿 数据的挑战,技术手段是核心,但对 并发管理器 等系统配置的日常监控才是预防灾难的根源。希望本案例能为处理 EBS 大表积压提供一份标准的实战参考。
博主结语: 如果您在实施过程中遇到 Degree of Parallelism 的选择难题,或对 APPEND 提示的生效条件有疑问,欢迎在评论区留言交流!
评论区